Automated Talent Management & Employee Skill Inference using Artificial Intelligence

The COVID-19 pandemic, the rise of technology and an increase on market competitivity are resulting in higher numbers of employee turnover making the talent management and onboarding tasks very difficult to deal with and very prone to human error. In addition to this, poor talent management, onboardings and tasks allocations may lead to inefficient productivity issues. All of these are often what prevent many companies to reach success!
The COVID-19 pandemic, the rise of technology and an increase on market competitivity are resulting in higher numbers of employee turnover making the talent management and onboarding tasks very difficult to deal with and very prone to human error. In addition to this, poor talent management, onboardings and tasks allocations may lead to inefficient productivity issues.
All of these are often what prevent many companies to reach success!
Proof of Concept Introduction
A proof-of-concept web application that uses artificial intelligence was built in order to answer the problems above described, that is, to ease the tasks of employee onboarding and tackle the issues of poor talent management, maximizing the company’s efficiency in resolving day-to-day challenges.
How does the proof-of-concept work?
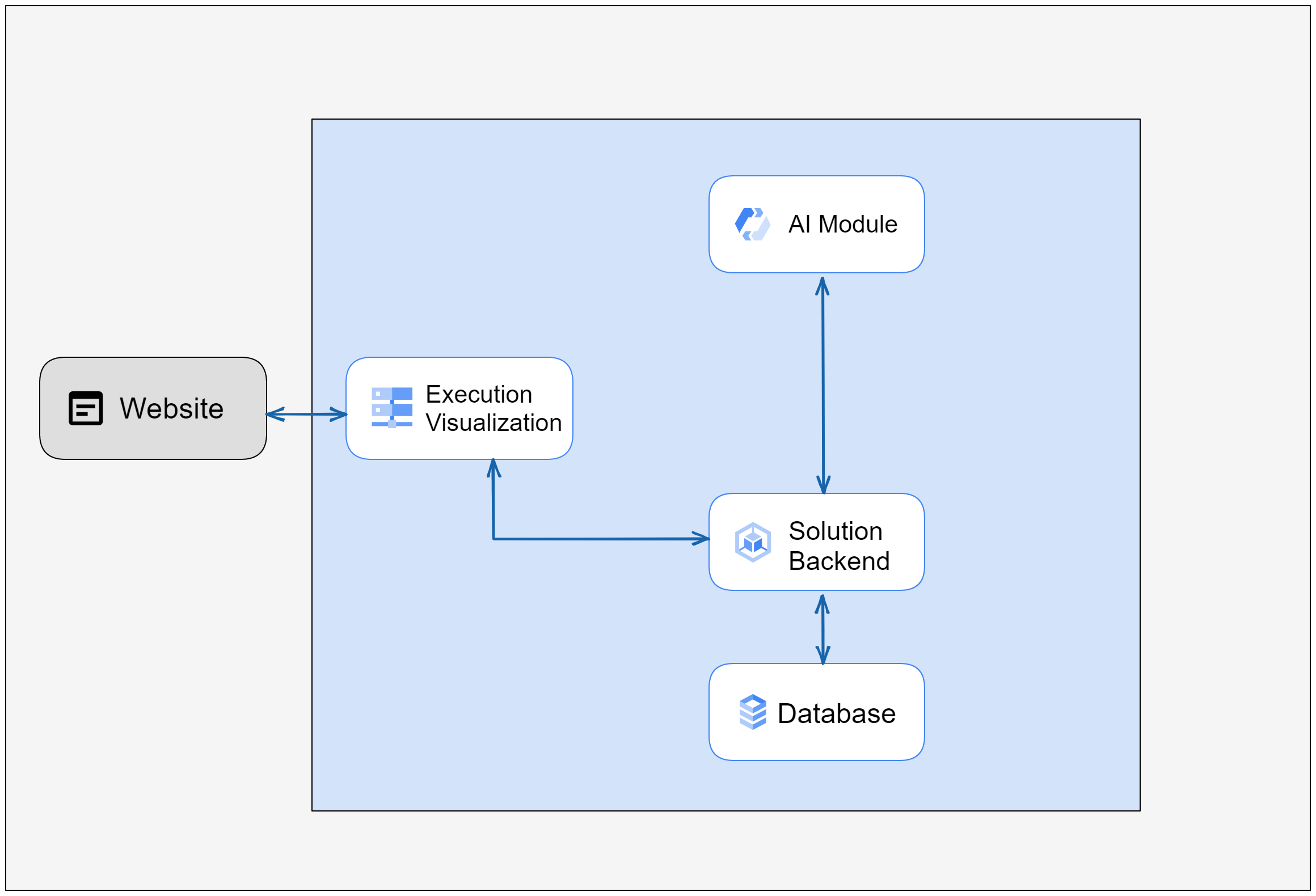
The proof of concept, requires, firstly, the input of textual data. Internally the data is parsed and given to a deep learning neural network that will extract essential information such as skills, geographical places, names, contacts, etc. To do so, this deep learning neural network will look at words and their context. This process is known as Named Entity Recognition (NER) (explained in the following section).
After the Named Entity Recognition phase is over, another layer of artificial intelligence model is present that takes in consideration the found words and their context and tries to infer skills that are not obvious in a first phase. An example of this might be if a person lived in a country for an extended period of time, this person probably knows the local language. This is the Skill Inference phase.
After the onboarding phase ends, the users that submitted the textual data are registered in the system and may be associated with a company.
When in a company, the manager may activate the automatic talent management multiagent system that will, according to customizable user preferences, allocate the resources in the existing tasks in an efficient manner using mathematical functions for the effect.
In addition to this, the proof of concept also suggests training content for elements by comparing the owned skills of the target user with other user profiles with similar skills. The skills that the target user does not know how to perform yet are common in similar profiles are recommended as part of a training course.
Below, a very generic diagram with the proof-of-concept architecture is displayed.
Named Entity Recognition
Deep Learning Neural Network Architecture
The Named Entity Recognition (NER) phase consists of identifying words out of texts.

There is a plethora of models for the effect albeit the ones that have been achieving the better results are deep learning neural networks in spite of consuming more computer power.
Usually, the training of these models happens with a dictionary containing words that have been already categorized (Supervised training). Before training the models, however, there are usually pre-processing tasks that try to convert the words in IDs or vectors.
In the proof of concept, a bidirectional long short term memory neural network was developed with the following architecture:
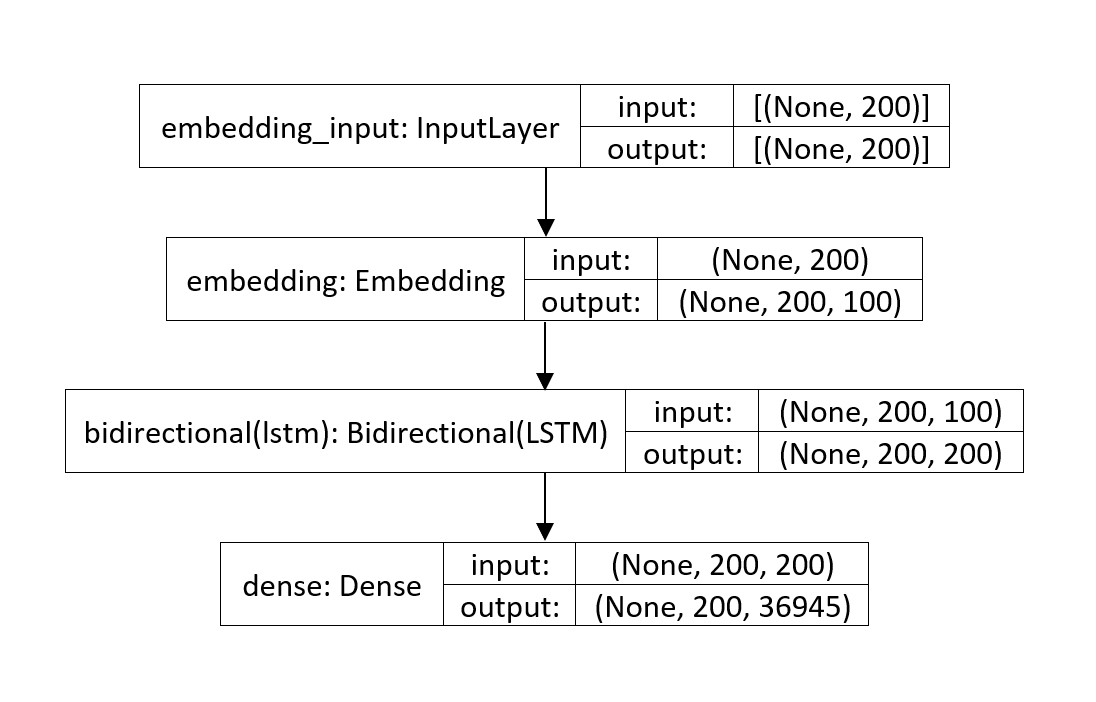
This was the chosen architecture since the bidirectional long short term memory layers allow to “imitate memory”, fundamental to perceive the context of the words in the texts.
This model was trained using 2 different merged datasets that allowed the model to recognize general information such as geographical places, names, emails, and the other allowed the model to recognize skills.
Skill Inference
The skill inference process happens right after the named entity recognition task, and it is an extra layer of artificial intelligence models. The goal of this process is to identify extra skills by looking at the context of the tokens found by the NER model. For instances, if the named entity recognition task recognizes that a user lived in England for a large period of time it is probable that the person knows the language.
For this particular scenario, a Naïve Bayes model was developed that was trained with a small dataset relating countries with their spoken languages.
Multiagent AI System
Multiagent systems belong to the subarea of distributed artificial intelligence mechanisms, and they usually represent real-time entities that through the means of negotiation (that can be either competitive or cooperative) try to solve a problem. Actions in agents are represented as behaviors and these can be triggered once or recurrently.
To solve the issue of poor talent management, 4 different agents were implemented with a mixed type of negotiation (cooperative and competitive). Cooperative because together they tackle the talent management issue but also competitive since employees may have preferences on working in certain tasks or with certain colleagues.
The multiagent system was developed in JADE so that it can be embedded with the JAVA backend and run-on different platforms. The system provides a Web Interface and REST API implemented using the Spring Framework for reusability/integrability purposes.
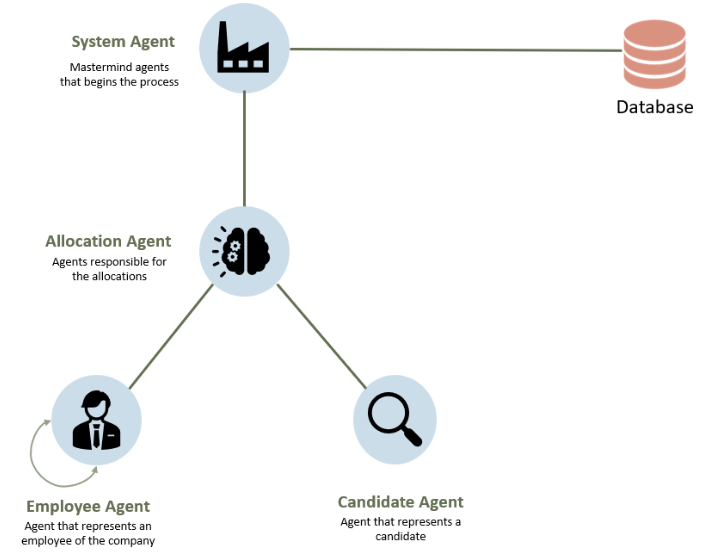
The 4 implemented agents are described below:
- System Agent: This is the master agent that is responsible for the startup of the process. It coordinates all of the other agents’ actions.
- Employee Agent: Represents an employee and holds information such as the person skills, colleague preferences, preferred tasks, how many tasks is the person working on etc. It always works cooperatively with the system agent and despite working cooperatively with other employee agents most of the times, it might, in specific situations, enter a competitive negotiation if the preferences of the employee that the agent represents are not guaranteed.
- Candidate Agent: Represents a candidate, which is a user not hired by the company but available to be. When sometimes the requirements of tasks are not fully fulfilled, candidate recommendation notifications are generated.
- Allocations Agent: Agent that works with the System Agent and receives the data from the employees and allocates them to tasks.
Another main advantage of these systems is their high extensibility allowing the development of very complex and customizable solutions with little effort. To do so, they utilize an “Yellow-Page Services” that allows agents to communicate between them in real time.
Employee Training Plan
Another capability of the system is the employee training plan suggestions that suggests skills based on other profiles data. Further explained, the system searches for profiles with similar skills, checks for differences and suggests these differences as part of a career development route. All suggestions must be validated by a manager.
This functionality starts with an agent (called TrainingAgent) that is triggered recurrently over a configurable period of time. The agent communicates with a deep learning neural network that was priorly trained with data of other worker profiles. The neural network, having received a list of skills suggests related skills that are present in other profiles but not on the target user.
Legal and Ethical AI
An important aspect regarding the usage of artificial intelligence is that these systems must not make decisions by themselves and must work as decision support systems. This is mandatory in the European Union as ‘The White Paper’ regulations on Artificial Intelligence initially suggested and was recently adopted in the EU law by the European Commission.
According to the European Commission (source):
- “AI systems MUST allow for human oversight and control over the decision cycles and operations…”
Due to this, all the artificial intelligence operations and decisions must be validated by a human user and this was something captured in the proof of concept.